
Linear Regression - Hồi quy tuyến tính cơ bản

Linear Regression (hồi quy tuyến tính) là một trong những thuật toán cơ bản nhất của Machine Learning. Ở bài viết này, tôi sẽ giới thiệu đến các bạn khái niệm về thuật toán này, lý thuyết toán học và cách triển khai thuật toán trên Python. Bài viết này được viết bằng Jupyter Lab.
Trước hết hãy import và setup các thư viện cần thiết.
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
I. Lý thuyết toán học
1. Bài toán tìm phương trình đường thẳng
Giả sử ta có phân bố ở một mặt phẳng dưới dạng một đường thẳng, nhiệm vụ của chúng ta là tìm ra phương trình đường thẳng khớp nhất với dữ liệu đó. Phương trình đường thẳng cho bài toán này khá đơn giản, hầu hết chúng ta đã quen thuộc với nó từ trung học:
trong đó có thể được coi là độ dốc hay slope, quyết định đến độ nghiêng của đường thẳng; còn có thể hiểu là chặn hay intercept của đường thẳng, quyết định sự dịch chuyển của đường thẳng so với gốc toạ độ. Với , đường thẳng sẽ đi qua gốc toạ độ.
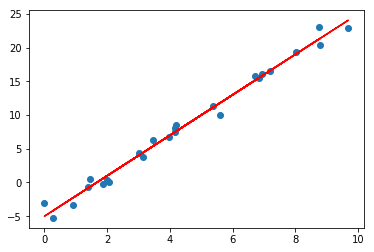
Hãy xem xét một dữ liệu có dạng đường thẳng với và (là đường thẳng màu đỏ trong hình bên dưới). Ở đây tôi sẽ dùng np.random để tạo ra các điểm phân bố theo một đường thẳng (các chấm xanh ở trong hình vẽ). Ở phần sau của bài viết này, ta sẽ cùng tìm hiểu cách dùng Linear Regression để tìm phương trình đường thẳng ứng với các điểm dữ liệu rời rạc đó.
rng = np.random.RandomState(1)
x = 10 * rng.rand(25)
y = 3 * x - 5 + rng.randn(25)
plt.scatter(x, y)
plt.plot(x, 3 * x - 5, linestyle='solid', color='red')
2. Bài toán tổng quát
Tìm phương trình đường thẳng là một trường hợp hết sức đơn giản của có thể áp dụng Linear Regression. Trên thực tế, dữ liệu của bài toán Linear Regression có thể nằm trong không gian nhiều hơn 2 chiều. Khi đó, ta có thể hiểu một cách trực quan là output của bài toán chính là sự kết hợp các input theo một tỷ lệ nào đó. Tỷ lệ này là các hệ số , và thường được gọi là trọng số của mô hình. Các giá trị có thể được viết thành vector , các trọng số có thể được viết thành vector . Việc tối ưu mô hình Linear Regression là tìm ra vector sao cho từ input ta có thể tính ra được output của bài toán.
Hãy cùng xem xét biểu diễn bài toán trong không gian chiều. Ví dụ bài toán xác định gía nhà dựa trên thuộc tính của căn nhà như diện tích, số phòng, khoảng cách đến trung tâm thành phố... Khi đó input của bài toán sẽ là vector thể hiện các thuộc tính của căn nhà dưới dạng các số thực và output sẽ là , với là giá trị thật của căn nhà. có thể được tính bằng công thức sau:
Nhìn chung giá trị dự đoán và giá trị thật thường là 2 giá trị khác nhau do sai số mô hình. Nhiệm vụ của bài toán này là đi tìm các tham số tối ưu sao cho sự khác nhau này là nhỏ nhất. Bài toán xác định phương trình đường thẳng trong mục 1 chính là trường hợp , là và là .
Ta có thể biểu diễn tham số dưới dạng một vector cột và input mở rộng dưới dạng . Ở đây, ta thêm số 1 vào để không cần phải xử lý riêng một trường hợp tham số tự do .
Việc tính toán giá trị output dự đoán trở thành:
Sai số dự đoán được gọi là sai số dự đoán. Giá trị này sẽ được tối ưu sao cho gần 0 nhất.
3. Hàm mất mát (loss function)
Chúng ta cần ước lượng xem mô hình của chúng ta bị sai, bị lỗi đến đâu, để từ đó tối ưu mô hình để có thể hoạt động ít lỗi nhất. Việc tính lỗi này không thể dựa vào cảm tính, mà phải dựa vào tính toán số học. Đó là lý do định nghĩa hàm mất mát (loss function) ra đời. Ta có thể hiểu hàm này được thiết kế để đánh giá độ lỗi, độ sai của mô hình. Kết quả của hàm này có giá trị càng lớn thì mô hình của chúng ta càng sai. Việc tối ưu bài toán được đưa về việc tối ưu các giá trị trọng số để hàm mất mát có giá trị nhỏ nhất. Ở bài toán này, dữ liệu huấn luyện gồm mẫu - cặp giá trị với . Hàm mất mát có thể được định nghĩa là:
Ở công thức trên, chúng ta lấy giá trị output thực tế ở trong tập dữ liệu huấn luyện trừ đi giá trị dự đoán sau đó lấy bình phương của kết quả đó để ước lượng sai số của 1 điểm dữ liệu. Tại sao không phải lấy trị tuyệt đối, vì chỉ cần lấy giá trị tuyệt đối là ta đã có thể có một dạng sai số rồi? Câu trả lời là do chúng ta cần một hàm để dễ tính toán đạo hàm ở bước tìm nghiệm cho bài toán. Hàm bình phương có đạo hàm tại mọi điểm, còn trị tuyệt đối có đạo hàm bị đứt tại điểm 0. Số trong công thức trên chỉ có ý nghĩa làm đẹp kết quả của đạo hàm.
Giá trị tối ưu của được ký hiệu là:
4. Tìm nghiệm cho bài toán
Để tìm nghiệm cho bài toán Linear Regression, chúng ta có thể giải phương trình đạo hàm của hàm loss bằng 0. Đạo hàm theo của hàm loss có dạng:
Nghiệm tối ưu cho bài toán này có dạng như sau (xem thêm tại đây).
II. Cài đặt với Python
Ở phần này, chúng ta sẽ giải một bài toán đơn giản, đó là việc tìm phương trình đường thẳng với dữ liệu tự sinh ra ở mục I.1. Việc mở rộng mã nguồn để giải các bài toán khác như dự đoán giá nhà, dự đoán chất lượng rượu, dự đoán giá xe... bạn đọc có thể tự tìm tòi và mở rộng mã nguồn bên dưới. Dữ liệu thử nghiệm cho các bài toán khác có thể được tải về từ đây. Việc mở rộng này sẽ giúp các bạn hiểu sâu hơn về Linear Regression, đống thời có được kĩ năng áp dụng Linear Regression cho các bài toán khác nhau. Đó cũng chính là mục đích cuối cùng của một kĩ sư AI.
Quay lại bài toán tìm phương trình đường thẳng. Bạn có thể sử dụng Jupyter Lab để cài đặt thuật toán, hay đơn giản là viết tất cả vào một file Python. Trước hết hãy đảm bảo là bạn đã import hết các thư viện cần thiết bằng phần code ở đầu bài viết này:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
Sau đấy là việc sinh ra các dữ liệu ngẫu nhiên, phân bố dưới hình dạng một đường thẳng.
rng = np.random.RandomState(1)
x = 10 * rng.rand(25)
y = 3 * x - 5 + rng.randn(25)
plt.scatter(x, y);
# plt.plot(x, 3 * x - 5, linestyle='solid', color='red')
1. Sử dụng công thức trong phần lý thuyết
Để cho tiện việc ký hiệu, ta viết lại phương trình đường thẳng ở mục I.1 như sau:
Ở phần lý thuyết, ta đã biết được nghiệm tối ưu của bài toán có dạng như sau:
Ta sẽ thử cài đặt thuật toán bằng công thức này để tìm ra phương trình đường thẳng ở trên.
# Hiện tại, x đang có dạng một array kích thước (25,), tương ứng với 25 giá trị của x vừa được sinh ra.
# Ta cần chuyển x về dạng ma trận 2D có kích thước (25, 1) - ứng với 25 hàng và 1 cột.
# Tiếp đó ta sẽ nối giá trị 1 vào đầu mỗi mẫu dữ liệu để tạo thành ma trận có kích thước (25, 2) -
# ứng với 25 hàng và 2 cột, trong đó cột đầu toàn là số 1. Bạn đọc có thể dùng thêm lệnh print(Xbar) để xem các
# giá trị trong ma trận được sinh ra.
x_reshaped = x.reshape((x.shape[0], 1))
one = np.ones((x_reshaped.shape[0], 1))
Xbar = np.concatenate((one, x_reshaped), axis = 1)
# Tính toán giá trị tối ưu của w theo công thức như phần trên
A = np.dot(Xbar.T, Xbar) # Tính phần trong ngoặc của công thức
b = np.dot(Xbar.T, y) # Tính phần bên ngoài ngoặc
w = np.dot(np.linalg.pinv(A), b) # Tính giá trị tối ưu của w, trong đó hàm np.linalg.pinv() được dùng để tính giả nghịch đảo
np.set_printoptions(precision=3)
print("Phương trình đường thẳng: y = {:0.2f}x + ({:0.3f})".format(float(w[1]), w[0]))
Output:
Phương trình đường thẳng: y = 3.00x + (-5.018)
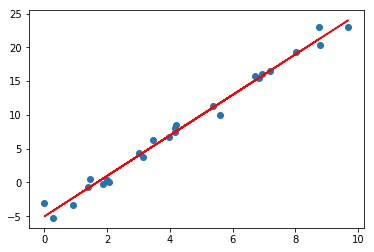
Vậy là chúng ta đã có thể tìm ra một phương trình đường thẳng cho dữ liệu vừa tạo . Phương trình này khá gần với phương trình gốc mà chúng ta dùng để tạo ra đường thẳng đó (). Có thể nói thuật toán của chúng ta đã hoạt động khá tốt. Hãy cùng vẽ đường thẳng chúng ta tìm được cùng với dữ liệu ban đầu:
rng = np.random.RandomState(1)
x = 10 * rng.rand(25)
y = 3 * x - 5 + rng.randn(25)
plt.scatter(x, y);
plt.plot(x, w[1] * x + w[0], linestyle='solid', color='red')
2. Sử dụng thư viện scikit-learn
scikit-learn là thư viện rất phổ biến trong Machine Learning. Hãy dùng xem cách cài đặt thuật toán tương tự như trên trong thư viện này.
from sklearn import datasets, linear_model
regr = linear_model.LinearRegression(fit_intercept=False)
regr.fit(Xbar, y)
w = regr.coef_
print("Phương trình đường thẳng: y = {:0.2f}x + ({:0.3f})".format(float(w[1]), w[0]))
Output:
Phương trình đường thẳng: y = 3.00x + (-5.018)
Vậy là phương trình đường thẳng chúng ta có được cũng tương tự với cách tính bằng Python thuần phía trên. Trên thực tế, bạn nên dùng thư viện scikit-learn thay vì tự tính theo công thức mình khai triển vì các thuật toán trong thư viện scikit-learn đã được đánh giá kĩ càng bởi các chuyên gia và được tối ưu về mặt tốc độ.
III. Thảo luận
Linear Regression là một thuật toán đơn giản và dễ cài đặt cho một bài toán với quan hệ tuyến tính giữa input và output. Tuy vậy Linear Regression có một nhược điểm lớn là nhạy cảm với nhiễu. Hãy cùng thử nghiệm bằng cách thêm một điểm nhiễu vào dữ liệu sinh ra.
# Sinh dữ liệu ngẫu nhiên tương tự như trước
rng = np.random.RandomState(1)
x = 10 * rng.rand(25)
y = 3 * x - 5 + rng.randn(25)
# Thêm điểm nhiễu (12.5, 5)
x = np.append(x, 12.5)
y = np.append(y, 5)
# Chuẩn bị Xbar
x_reshaped = x.reshape((x.shape[0], 1))
one = np.ones((x_reshaped.shape[0], 1))
Xbar = np.concatenate((one, x_reshaped), axis = 1)
# Tối ưu mô hình
regr = linear_model.LinearRegression(fit_intercept=False)
regr.fit(Xbar, y)
w = regr.coef_
# Vẽ kết quả
plt.scatter(x, y);
plt.plot(x, w[1] * x + w[0], linestyle='solid', color='red')
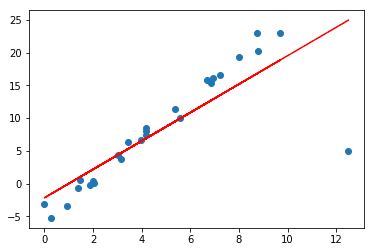
Có thể thấy, chỉ một điểm nhiễu đã có thể kéo lệch đường thẳng được tìm ra bởi Linear Regression khá nhiều. Điều này cho thấy thuật toán rất nhạy cảm với nhiễu.
Linear Regression cho bài toán phi tuyến: Ta vẫn có thể sử dụng Linear Regression cho một bài toán phi tuyến tính bằng cách biến đổi nó một chút. Hãy bắt đầu với phương trình cơ bản cho Linear Regression:
Ta đặt với là một hàm dùng để biến đổi dữ liệu đầu vào. Ví dụ với , bài toán được chuyển thành hồi quy đa thức.
Cách làm này giúp chúng ta dùng Linear Regression với các quan hệ phức tạp hơn giữa và . Tuy nhiên, nó lại dế gây ra hiện tượng overfitting, dẫn đến việc phải có thêm các phương pháp regularization.