
Tìm hiểu mô hình CenterNet - Objects as Points

CenterNet là một mạng object detection có thiết kế cực kỳ đơn giản, nhưng lại đạt được cân bằng giữa tốc độ và độ chính xác tốt vừa được ra mắt năm 2019. Ở bài viết này mình muốn giới thiệu đến các bạn những ý tưởng cơ bản của mạng này, cách thức hoạt động và cách huấn luyện CenterNet. Mình sẽ tập trung vào mục đích phát hiện vật thể.
Lưu ý: Hiện có 2 bài báo đều gọi là "CenterNet", tuy nhiên thiết kế của chúng không giống nhau. Bài báo mình định giới thiệu đến bạn đọc là bài Objects as Points - Xingyi Zhou, Dequan Wang, Philipp Krähenbühl. Trong khi đó, bài báo còn lại là CenterNet: Keypoint Triplets for Object Detection - Kaiwen Duan, Song Bai, Lingxi Xie, Honggang Qi, Qingming Huang, Qi Tian, không liên quan gì đến bài viết này.
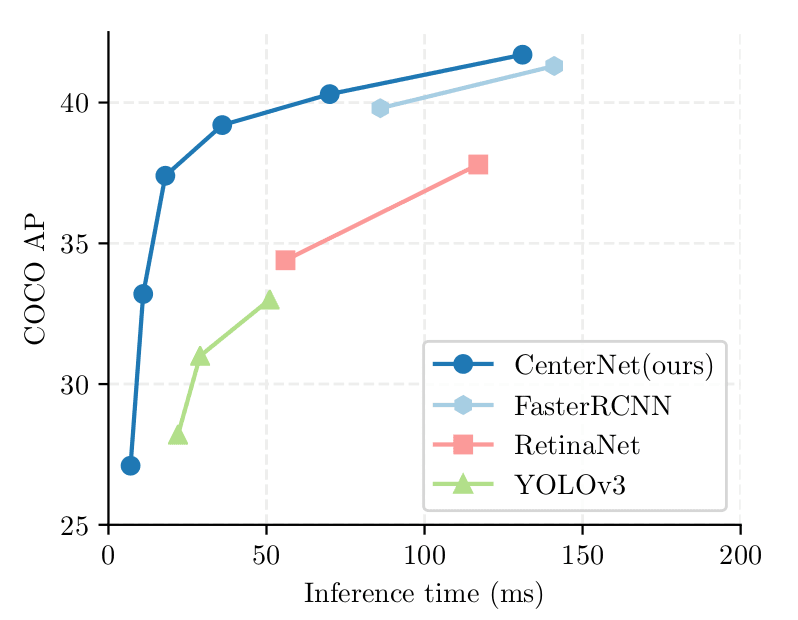
CenterNet - Objects as Points hiện đang là top 1 trong bài toán Realtime Object Detection trên tập COCO với độ chính xác không tồi. 28.1% AP ở tốc độ 142 FPS, 37.4% AP ở tốc độ 52 FPS và 45.1% AP ở 1.4 FPS sử dụng các backbone khác nhau. (theo bảng thống kê từ trang PapersWithCode ngày 15/04/2020: https://paperswithcode.com/sota/real-time-object-detection-on-coco).
I. Hướng tiếp cận mới của CenterNet
Vấn đề của các mạng object detection thành công nhất hiện nay là chúng phải thực hiện các quá trình tính toán với nhiều bước rời rạc, khó tối ưu về tốc độ (các mạng 2-stage như Faster RCNN), hoặc phải đặt rất nhiều các anchorbox với kích thước khác nhau chi chít khắp hình ảnh, gây lãng phí tính toán và yêu cầu các bước hậu xử lý như non-maximum suppression (các mạng 1-stage như YOLO, SSD).
Hướng tiếp cận mới của CenterNet là đưa bài toán phát hiện vật (object detection) về bài toán tìm điểm đặc trưng (keypoint estimation), từ đó cũng suy ra kích thước và tính toán được bounding box cho bài toán phát hiện vật. Kiến trúc mạng cũng có thể dễ dàng được sửa lại để output ra vị trí 3D, hướng và tư thế cho các bài toán khác.
Từ hình dưới có thể thấy rõ hướng tiếp cận của CenterNet khá hiệu quả. Nó vượt qua các thuật toán 1 stage phổ biến nhất hiện nay là YOLO v3, RetinaNet trong sự cân bằng giữa tốc độ và độ chính xác. Hơn nữa độ chính xác của CenterNet còn ngang ngửa Faster RCNN - một mạng phát hiện vật 2 stage.
II. Nguyên lý cơ bản và các hàm tối ưu của CenterNet
Ở phần này, mình sẽ giới thiệu đến các bạn các nguyên lý cơ bản cùng các hàm tối ưu mà CenterNet sử dụng để đạt được kết quả tốt như vậy.
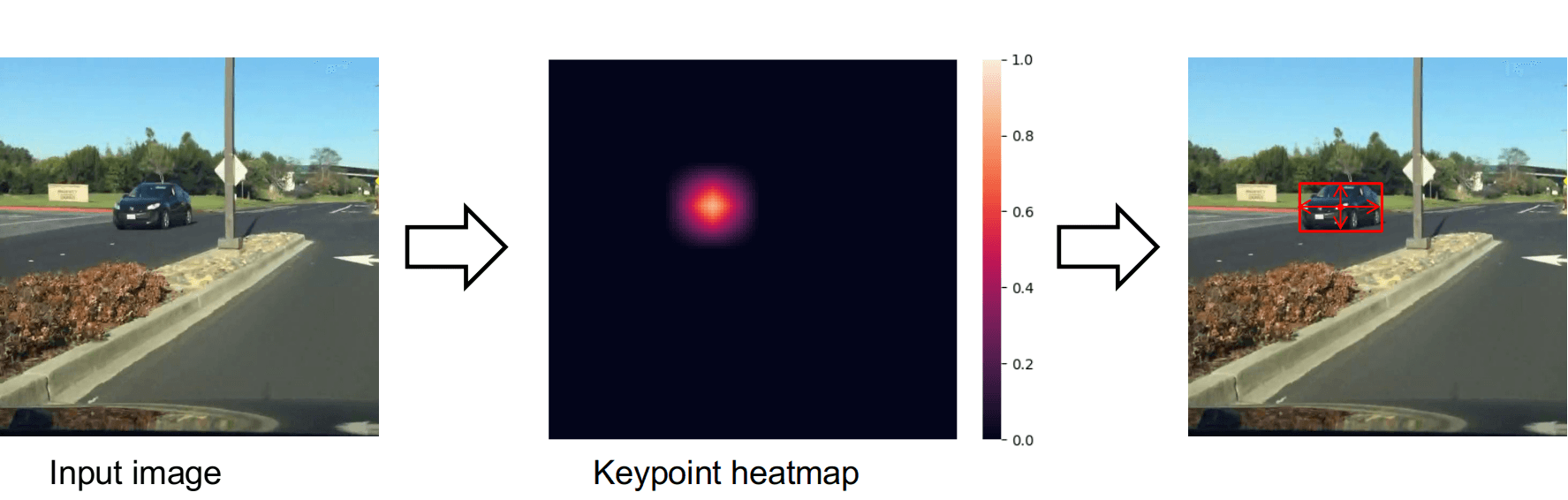
Nguyên lý cơ bản của CenterNet được mô tả như hình trên. Sau khi qua mạng backbone, ảnh đầu vào sẽ được biến đổi thành một heatmap (bản đồ nhiệt). Mỗi ô trong bản đồ heatmap này thể hiện xác suất trong ô đó chứa tâm của vật. Tiếp đó CenterNet thực hiện lọc các điểm cực đại trên heatmap để xác định tâm của các vật trên ảnh. Từ đó có thể suy ra được kích thước của vật (với bài toán phát hiện vật) và các đặc điểm khác với các bài toán khác. Ta sẽ cùng đi sâu vào từng phần để hiểu rõ cách hoạt động và cách huấn luyện mạng cho mỗi bước.
1. Nguyên lý cơ bản của tìm điểm đặc trưng (keypoint estimation) và cách huấn luyện
Nguyên lý

Làm thế nào để có thể chỉ sử dụng kiến trúc keypoint đơn giản mà đạt hiệu quả ngang bằng, thậm chí hơn các mạng phát hiện vật sử dụng anchorbox tốt nhất?
Thực ra keypoint cũng có thể coi là một dạng anchorbox cơ bản. Feature map của centernet có stride=4, nhỏ hơn các thiết kế của nhiều mạng sử dụng anchorbox (stride=16), nên không cần sử dụng nhiều anchorbox trong cùng 1 điểm trên feature map để bắt hết các vật.
Ở đây mình cũng xin giải thích thêm cho các bạn chưa hiểu. Sau khi đưa ảnh đầu vào qua mạng backbone (CNN), ta thu được feature map, là một ma trận có kích thước dài x rộng x chiều sâu. Ứng với mỗi điểm trong feature map này (1 x 1 x chiều sâu), ta sẽ thực hiện bước keypoint estimation (tìm điểm đặc trưng). Stride=4 của CenterNet có nghĩa là feature map có kích thước chiều dài và chiều rộng đều nhỏ hơn chiều dài và chiều rộng của ảnh đầu vào 4 lần. Điều đó cũng có nghĩa mỗi ô trong feature map tương đương với 4 ô trong ảnh đầu vào. Feature map càng nhỏ hơn ảnh đầu vào ở kích thước chiều dài x chiều rộng, ta sẽ cần nhiều anchorbox để bắt hết các vị trí của vật trong ảnh, vì có thể nhiều vật nằm trong cùng một ô của feature map.
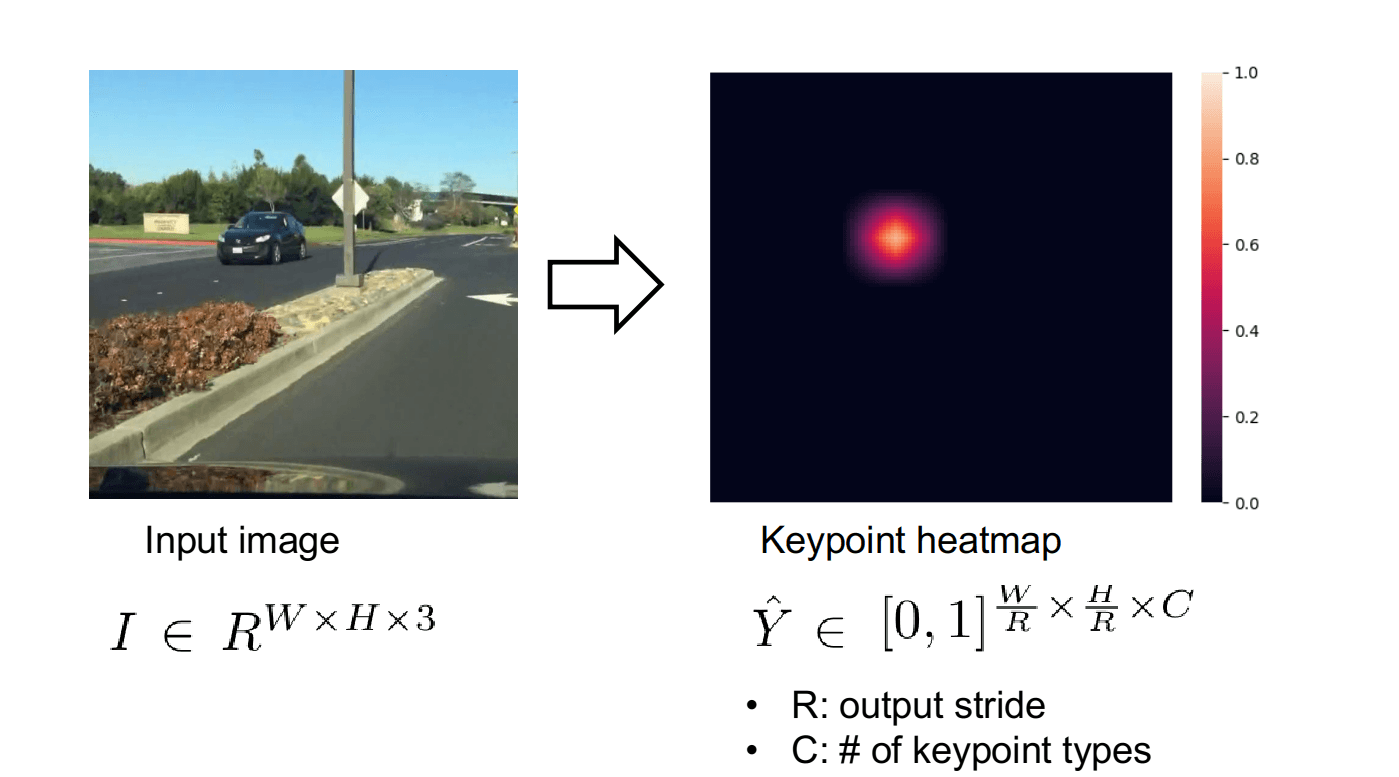
Một chút công thức toán, với ảnh đầu vào có chiều rộng , chiều dài , chúng ta cần huấn luyện mạng để tạo ra heatmap , trong đó là stride của heatmap và là số loại keypoint. Trong bài toán nhận dạng tư thế người, là số khớp. Trong bài toán phát hiện vật, là số class ( trong tập dữ liệu MS COCO). Trong mỗi ô của heatmap này, ứng với một keypoint, ứng với một điểm background (nền).
Ở CenterNet, tác giả sử dụng stride , do vậy kích thước heatmap sẽ nhỏ hơn ảnh đầu vào 4 lần. Giả sử chúng ta đang làm bài toán phát hiện vật với số class là 80, ảnh đầu vào (3 là số kênh màu trong hệ màu RGB). Như vậy, heatmap sẽ có kích thước .
Huấn luyện
Để huấn luyện mạng keypoint prediction, trước hết chúng ta tạo ground truth heatmap để làm mục tiêu hướng đến.
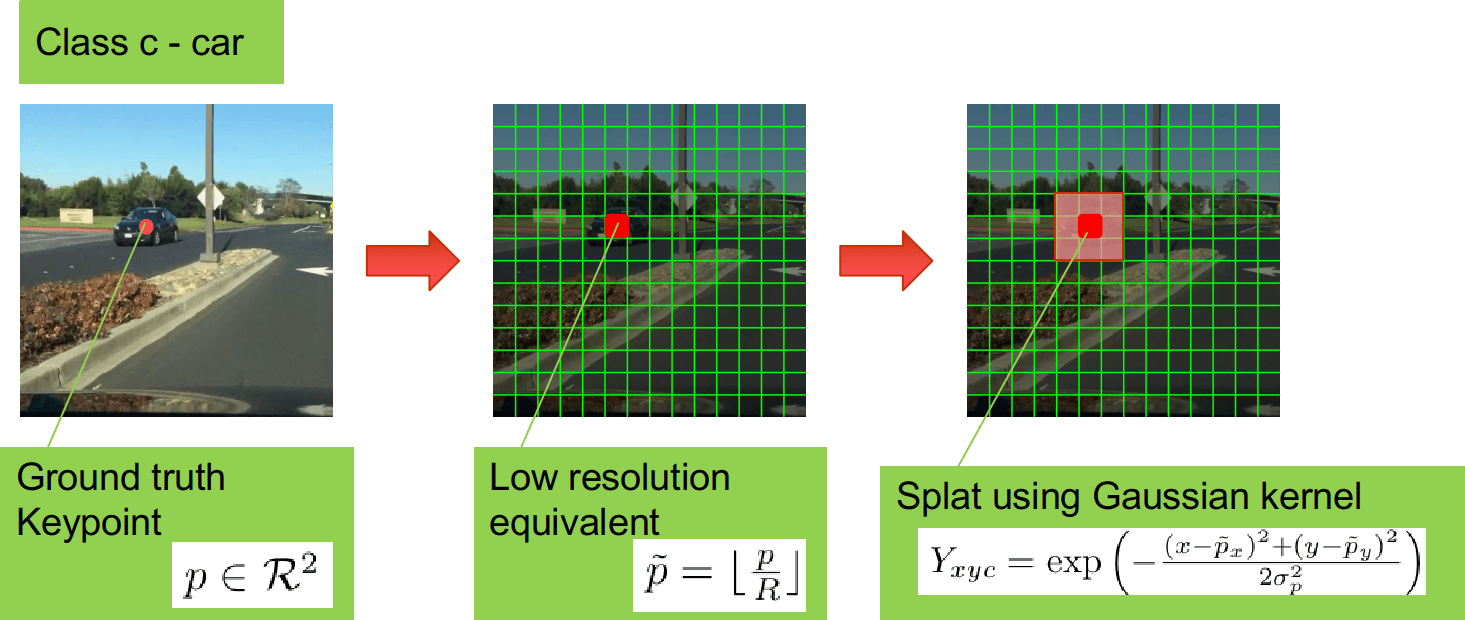
Ground truth heatmap được tạo riêng biệt cho mỗi class trong bài toán object detection. Giả sử ở đây ta tạo ground truth cho class car - xe ô tô.
Từ bounding box của đối tượng xe ô tô trong ảnh, ta dễ dàng tìm được điểm keypoint là tâm của vật . Giả sử ảnh đầu vào có kích thước , bounding box của xe ô tô trong ảnh là thì tâm của vật là . Từ đây ta tìm điểm tương ứng với trên heatmap là . Sở dĩ có công thức này vì heatmap nhỏ hơn ảnh đầu vào lần, do vậy ta chỉ cần lấy toạ độ của chia cho và lấy phần nguyên của kết quả. Tiếp đó ta lan rộng điểm ra với phân phối chuẩn .
Ở hình minh hoạ trên, mình đã cố tình vẽ phóng to heatmap để mọi người dễ hình dung. Việc chuyển từ ảnh sang heatmap có thể thu được kết quả như hình ảnh dưới. Xin chú ý là tham số của công thức phân phối Gaussian được tính dựa trên kích thước của vật.
Hàm tối ưu được sử dụng cho bước này là Focal loss. Focal loss thực chất là một bản chỉnh sửa của cross entropy loss với các cải tiến nhằm hạn chế sự ảnh hưởng của mất cân bằng class. Mất cân bằng class trong trường hợp này chính là sự mất cân bằng giữa số điểm trên heatmap ứng với tâm vật (thường khá nhỏ) và số điểm là background, giữa các điểm khó phân biệt và các điểm dễ phân biệt. Công thức hàm loss cho keypoint prediction như sau:
2. Ước lượng độ lệch của keypoint
Bạn đọc có thể để ý là việc tạo ra ground truth heatmap nhỏ hơn ảnh đầu vào lần và tính vị trí keypoint trên ground truth heatmap bằng công thức thực chất đã tạo ra sai số. Có một phép lấy phần nguyên ở đây. Điều này đã được tác giả xử lý bằng cách thêm bộ ước lượng độ lệch (offset predictor) với công thức . Đầu ra của bộ ước lượng độ lệch này là một ma trận với kích thước - số 2 ở đây đại diện cho chiều dọc và chiều ngang.
CenterNet sử dụng chung một offset predictor cho tất cả các class và huấn luyện offset predictor với hàm loss L1:
Dễ thấy chính là phần chênh lệch tạo ra khi làm tròn giá trị (xin nhắc lại ).
3. Dự đoán kích thước của vật
Giả sử bounding box của vật có dạng . Có thể dễ dàng tính ra điểm tâm của vật . Song song với việc dùng keypoint predictor để tìm ra điểm tâm này, CenterNet tìm ra kích thước của vật ứng với mỗi vật .
Để giảm chi phí tính toán, CenterNet dùng một bộ ước lượng kích thước cho tất cả các class: (số 2 ở đây đại diện cho chiều dài và chiều rộng).
Việc huấn luyện bộ ước lượng kích thước lại tiếp tục dựa vào hàm tối ưu L1:
Ở đây CenterNet không chuẩn hoá kích thước của vật, mà dùng luôn đơn vị pixel cho kích thước này.
4. Hàm tối ưu tổng
Hàm tối ưu tổng được tạo ra dựa trên các hàm tối ưu được dùng ở trên với các trọng số và :
Hàm tối ưu này được sử dụng để huấn luyện mạng CenterNet phát hiện vật thể.
III. Các backbone được sử dụng trong bài báo
CenterNet sử dụng tập dữ liệu MS COCO để đánh giá độ chính xác cho phát hiện vật.
Có 3 backbone chính được giới thiệu: Hourglass đạt độ chính xác tốt nhất, Deep Layer Aggregation DLA đạt được cân bằng về tốc độ và độ chính xác và ResNet (18) cho tốc độ cao nhất. Các thử nghiệm về độ chính xác và tốc độ các bạn có thể tìm thấy trong bài báo gốc.
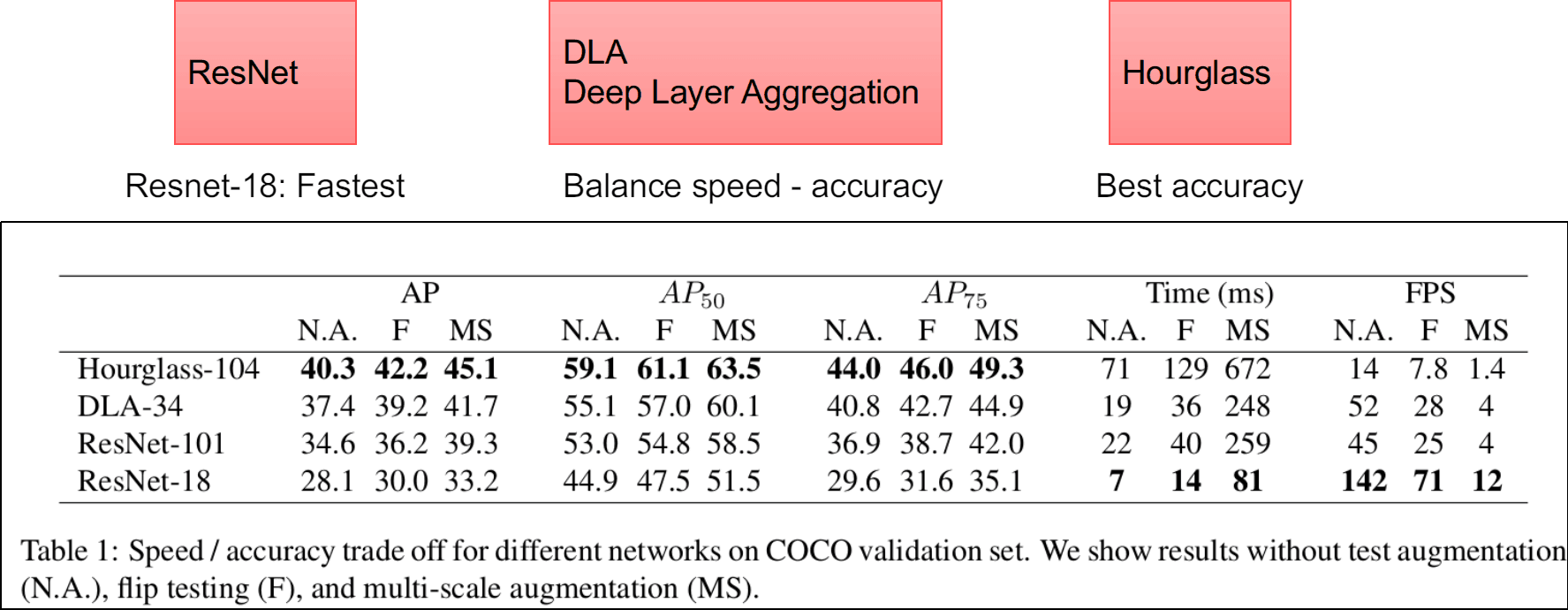
Cá nhân mình khi sử dụng mạng CenterNet - Resnet18 kết hợp với công nghệ TensorRT của Nvidia có thể phát hiện vật ở tốc độ khoảng 2ms/frame trên Nvidia RTX 2070 - Intel Core i5 8400 và 90ms/frame trên Jetson Nano với độ chính xác tương đối tốt. Các bạn có thể tham khảo cách chuyển mô hình đã huấn luyện sang TensorRT tại đây.
IV. Các điểm yếu của mạng CenterNet
CenterNet là một hướng đi mới, và cũng có những hạn chế của nó. Sau đây là một vài nhược điểm mình đã tìm hiểu được.
1. Center point collision: Hoạt động kém với các vật có tâm ở gần nhau
Phân tích của tác giả: Trong tập huấn luyện của MS COCO, là một tập dữ liệu khá lớn và đa dạng có 614 cặp vật có tâm gần nhau, bị trùng trong heatmap khi ở stride 4, tuy nhiên có 86001 vật tất cả => Chỉ < 0.1% số vật thể không thể phát hiện vì lý do này. Tỷ lệ lỗi này khá nhỏ so với RCNN, Fast RCNN khi region proposal không tốt và các thuật toán dựa trên anchorbox khi không đặt đủ số anchorbox.
Cá nhân mình thấy nhược điểm này có quan trọng hay không thì còn tuỳ vào bài toán, tuỳ vấn đề các bạn đang giải quyết mà có thể suy xét tới.
2. Thời gian huấn luyện khá lâu
Trong paper Training-Time-Friendly Network for Real-Time Object Detection, các tác giả có viết rằng thời gian huấn luyện mạng CenterNet cho MS COCO là khoảng 140 epoch trong khi thời gian huấn luyện cho các mạng kiểu SSD, YOLOv3 chỉ rơi vào khoảng 12 epoch.
Cá nhân mình thấy thời gian huấn luyện mạng cũng không phải yếu tố quan trọng lắm trong đa số các trường hợp. Tuy nhiên khi cần một mạng có thời gian huấn luyện nhanh để có thể có được mô hình trong thời gian ngắn, chúng ta cũng nên suy xét tới yếu tố này.
Kết luận
Trên đây là các tìm hiểu của mình về mạng CenterNet - Objects as Points, tập trung vào bài toán phát hiện vật thể trong miền 2 chiều. CenterNet còn được sử dụng để phát hiện vị trí vật thể trong không gian 3D, phát hiện tư thế của vật. Nếu các bạn quan tâm có thể tìm đọc trong bài báo gốc, ở mục Tham khảo.
Các bạn có góp ý gì, hoặc muốn bổ sung điều gì, vui lòng comment bên dưới nhé! Mình rất mong có những lời góp ý chân thành từ bạn đọc. Mình xin cảm ơn!
Tham khảo
- Objects as Points - Xingyi Zhou, Dequan Wang, Philipp Krähenbühl: https://arxiv.org/abs/1904.07850.
- Training-Time-Friendly Network for Real-Time Object Detection - Zili Liu, Tu Zheng, Guodong Xu, Zheng Yang, Haifeng Liu, Deng Cai: https://arxiv.org/abs/1909.00700.
- Focal loss: https://arxiv.org/abs/1708.02002.