Paper review: "YOLOX: Exceeding YOLO Series in 2021" and application in traffic sign detection - VIA Autonomous

YOLOX is an anchor-free version of YOLO, with a simpler design but better performance! It aims to bridge the gap between research and industrial communities. With this version of YOLO, the authors won the 1st Place on Stream Perception Challenge (Workshop on Autonomous Driving at CVPR 2021. This note reviews YOLOX paper and introduces an experiment on our custom toy dataset for traffic sign detection in VIA Project.
1. Key concepts
The key concepts from YOLOX paper are:
- Apply anchor-free manner to YOLO architecture
- Apply current advanced techniques for object detection:
- Decoupled head
- Advanced label assignment strategy: SimOTA
- Strong data augmentation: Mosaic, MixUp
2. Network design
Anchor-free manner
YOLOX says that they don't use anchor-based manner in their design. So what is the problem of anchor-based manner?
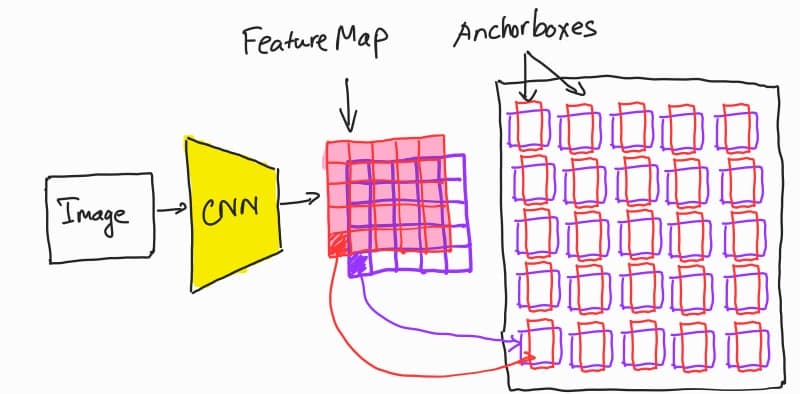
In anchor-based object detectors, they place a lot of anchor-boxes among the image. The input image is passed through a CNN to obtain a feature map. This feature map is then used to predict the bounding boxes of the objects. Each point in the feature map is corresponding to a set of anchor boxes. These points take responsibility to predict the object belonging to each anchor box with the location offset from these boxes. This design has some disadvantages:
- We need a hand-picking set of anchorbox configurations or need to run a clustering analysis to determine the optimal set of anchorboxes. The obtained configurations are often domain-specific and cannot generalize to other datasets.
- This increases the complexity of heads and the number of predictions. It's considered not resource-friendly when we need to perform postprocessing in some resource-constrained systems such as embedded systems or mobile devices.
The anchor-free manner that chosen by YOLOX treats the objects detection like a keypoint detection problem. This helps to avoid the above disadvantages of anchor-based method. You can read more about anchor-free manner in the paper CenterNet - Objects as Points or in my post here. Considering that YOLOv4 and YOLOv5 may be a little over-optimized for anchor-based pipeline, YOLOX authors decided to use YOLOv3-SPP as the base to develop their detector.
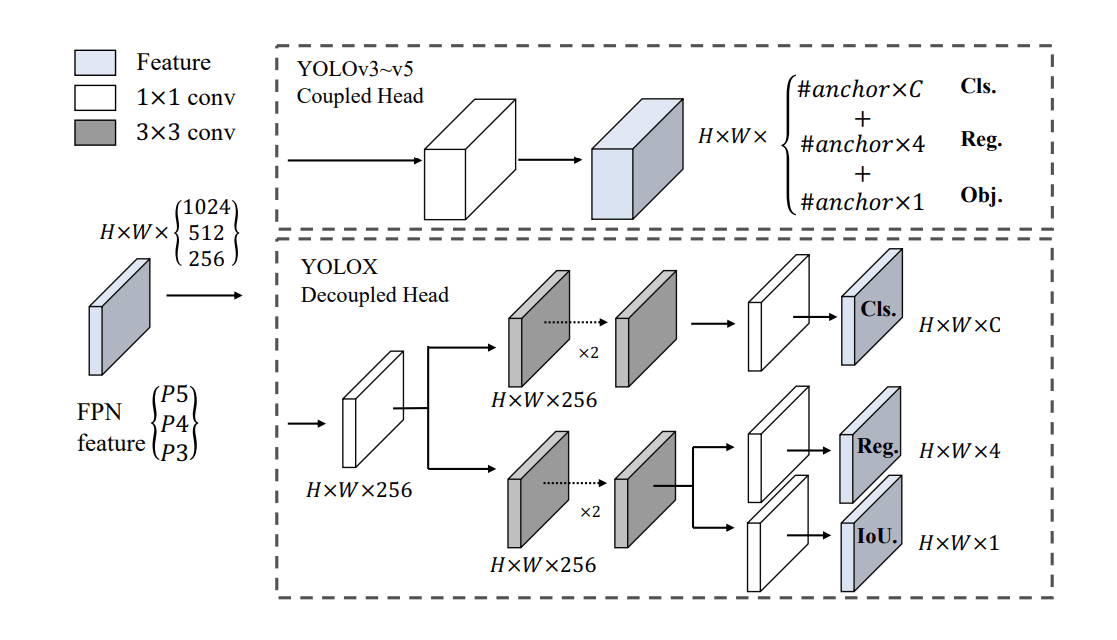
Decoupled head
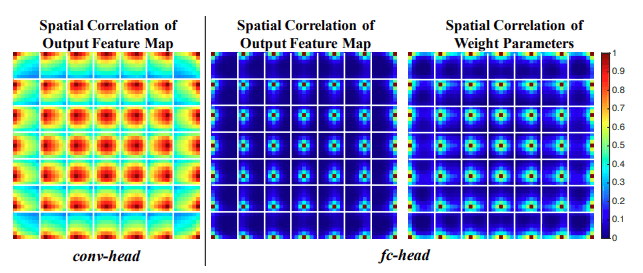
In object detection, the conflict between classification and regression tasks is a well-known problem. Paper Rethinking Classification and Localization for Object Detection performs thorough analysis on fully-connected head (for classification task) and convolutional head (for localization task) and find an interesting fact that the two head structures have opposite preferences towards the two tasks. They are complementary!. They examine the output feature maps of both heads and confirm that fc-head is more spatially sensitive. As a result, fc-head is better to distinguish between a complete object and part of an object (classification) and conv-head is more robust to regress the whole object (bounding box regression). They also did some experiments to compare accuracy in order to prove their assumption.
In YOLOX, Replacing YOLO's head with a decoupled one greatly improves the converging speed and increases the AP for end-to-end YOLO. Thus, they choose this double-head architecture for their proposed models.
3. Training strategies
Strong data augmentation
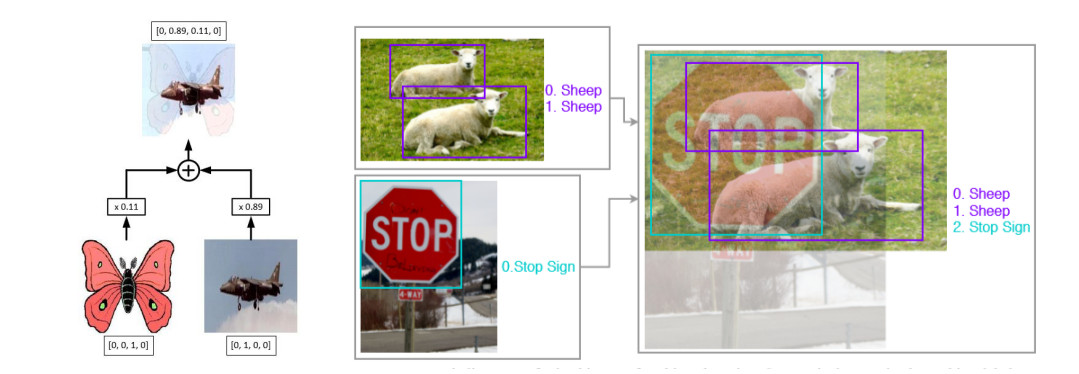
Applying recent advanced data augmentation techniques also contributes to YOLOX'success. YOLOX uses Mosaic and MixUp in the augmentation strategies to boost performance. Mosaic is an efficient augmentation strategy proposed by ultralytics-YOLOv3 and used by YOLOv4, YOLOv5. While MixUp is originally designed for object classification, and later adapted for object detection. YOLOX authors say that they don't need to use ImageNet pre-training anymore after applying these augmentation methods. Let's see into below examples to understand Mosaic and Mixup in object detection.

)%5D(/posts-data/2021-07-28-yolox/mixup.jpg){kind=link}
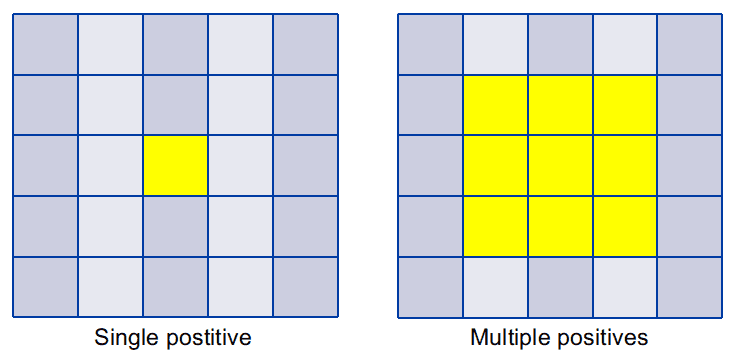
Multiple positives
To reduce the extreme imbalance between positives / negatives when training, instead of only selecting 1 positive sample at the center location for each object, they assign the center 3x3 as the positives. This strategy is called "center sampling" in FCOS. The performance of the detector improves after this modification.
SimOTA
Advanced label assignment is important progress recently. Label assignment here is to assign what is positive/negative training samples for each groundtruth object. In anchor-based object detectors, they often calculate Intersect-Over-Union (IoU) between each groundtruth box with all anchorboxes to decide which anchorboxes are positive sample and which are negative samples. Anchor-free methods like FCOS treat the center/bbox region of any gt object as corresponding positives. These strategies could not leverage all object properties for pos/neg assignment. Some dynamic assignment methods have been proposed. OTA models the label assignment as an optimal transport problem and uses Sinkhorn-Knopp Iteration algorithm to solve and find the best assignment.
However, in the original OTA, Sinkhorn-Knopp Iteration algorithm brings 25% extra training time, YOLOX simplifies to dynamic top-k strategy. First, it calculates the pair-wise matching degree for each prediction-gt pair. The cost between gt and prediction is:
where is a balancing coefficient, dasasdasd as and are classification loss and regression loss between gt and prediction . For , select top predictions with the least cost within a fixed center region as its positive samples. Note that varies for different gt.
4. Experimental results
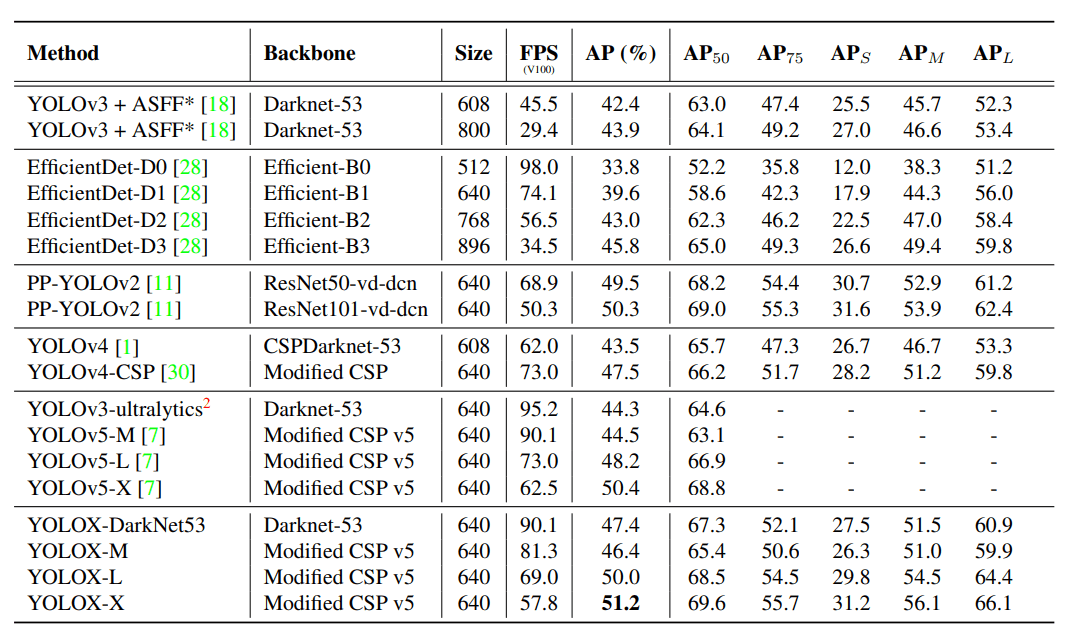
The authors adopt some backbones configurations to scale YOLOX to different speed-accuracy tradeoffs. Modified CSPNet like YOLOv5 is used to compare with YOLOv5 models in terms of accuracy. YOLOX also has Tiny and Nano models that adopt depth-wise convolution for mobile devices. Below is the comparison table of YOLOX with other YOLOs and EfficientDet versions.
5. Deployment
YOLOX authors say that "It aims to bridge the gap between research and industrial communities". Thus, high deployability is a strength of YOLOX models. In the source code, the authors demonstrate the ability to deploy YOLOX using many popular inference engines, including:
- MegEngine in C++ and Python
- ONNX Runtime in C++ and Python
- TensorRT with Deepstream support
- ncnn in C++ and Java
- OpenVINO in C++ and Python
- Tengine
- ROS2
I think this will helps YOLOX become popular in the core of industrial products soon. Good job!
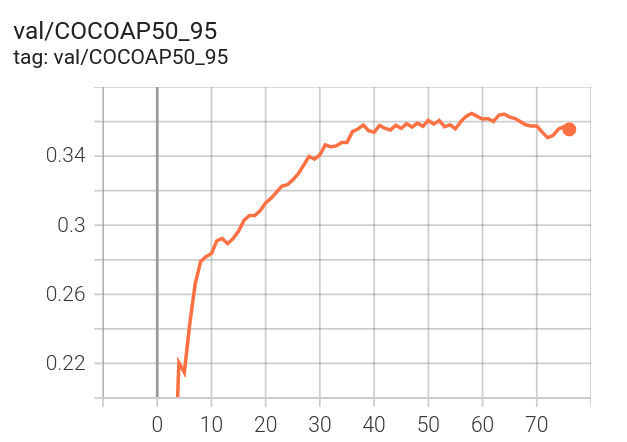
6. Experiment on VIA Traffic sign dataset
In this experiment, we use VIA Traffic sign - a toy dataset for traffic sign detection from VIA Project. The source code for dataset preparation and training with YOLOX is provided at https://github.com/vietanhdev/vtfs_yolox. I created a configuration file for network architecture and training based on YOLOX-Nano here. After training for 76 epochs, the best model has mAP = 0.3647 in the validation set.